$1,500. That’s the amount of money I have spent over the past 5 years to store our family’s whole genome sequence (WGS) data. For $299 per person in 2020, I could sequence all of us again at 30x coverage, get the same data files, and spend less money. In 2015, I wrote about posting my WGS data to DNAnexus. Last month (July 2020), I moved all of our data to Amazon (AWS) S3 storage. In this post, I explain why.
Five years ago, my impression was that DNAnexus was a platform for researchers, not consumers. It turns out that my first impression was correct–DNAnexus is not a platform for consumers. To their credit, their platform-as-a-service model includes an extensive set of genomic analysis tools, an easy-to-use SDK, top-notch documentation. a way to run your own docker images using Workflow Description Language (WDL), and a professional services team. DNAnexus’ IT infrastructure and regulatory compliance make the platform valuable for over 100 enterprise customers, and their recent $100M funding round coupled with their UK Biobank/AWS announcement will enable the company to expand into new markets and let researchers find more actionable insights.
Nevertheless, I recently moved my WGS data to Amazon S3 due to storage costs and a lack of price transparency.
Storage costs
I’ve learned that most of the work that I want to do can be done with VCF files. Yes, there are times when I want to look at BAM files, but moving those files to lower-cost storage makes sense. DNAnexus introduced a Glacier-based archiving service in 2019 to support those operations, although I did not use it. My BAM file is 73 GBytes, which represents about 93% of the 79 GBytes for my WGS data (no FASTQ data). If I deeply archive BAM and FASTQ data (329 GBytes total), I can reduce the amount of higher-cost storage by 98%. The cost comparison for a single genome with FASTQ files looks roughly like this:
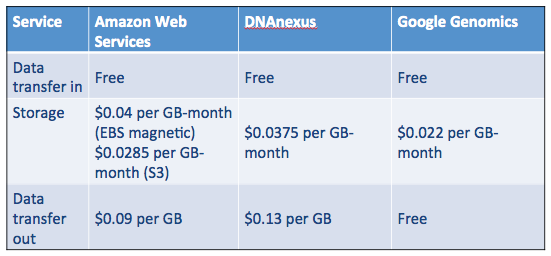
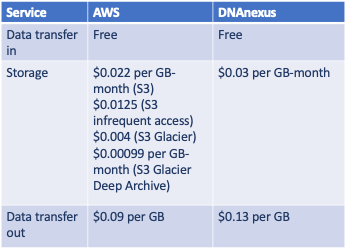
- Storage cost on DNAnexus: (329 GBytes * $0.03 per GB-month [everything]) = $9.87 per month
- Storage cost on AWS: (7 GBytes * $0.0125 per GB-month [VCF]) + (322 GBytes * $0.00099 per GB-month [everything else]) = $0.41 per month
Overall, I can reduce my monthly storage costs by over 95% by using lower-cost storage tiers on AWS (see Table 1 below). Again, the comparison is apples-to-oranges because I did not use DNAnexus’ archiving service, mostly because it required a separate license to activate. Using Amazon S3, our monthly WGS storage costs will decrease from $24 per month to less than $1 per month.
Lack of price transparency
If we compare AWS’ S3 storage price from 5 years ago to DNAnexus’, we find that the storage markup was 35% over the S3 list price. It turns out that Amazon decreased its S3 storage price over the past 5 years, which led DNAnexus to drop their storage price to the current $0.03 per GB-month, still at a 35% markup. (For comparison, on demand GPU- or FPGA-based compute cycles (Amazon EC2) are marked-up over 100%.)
I do not fault DNAnexus for marking-up AWS pricing–they are a business and provide value beyond storage and compute cycles. However, you will not find any pricing information on the DNAnexus website. In addition to storage costs, add-ons like archiving and GxP regulatory compliance require separate licenses that are not disclosed when signing-up. Presumably, the company’s professional services team assists with these onboarding activities.
How to move your data from DNAnexus to AWS
So, having made the decision to move my WGS data to AWS, how did I do it?
On the DNAnexus platform, I used AWS S3 Exporter, a company-provided tool to upload data to an AWS S3 bucket (DNAnexus account required). You can invoke the exporter using either their SDK (dx-toolkit) or an online wizard–both methods work great. The DNAnexus policy documentation does not include verification by default, so I updated the AWS IAM policy file with a resource-based policy and also enabled transfers to work with verification:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::yourAccountNumber:root"
},
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::yourBucketName",
"Condition": {
"StringLike": {
"aws:Referer": "https://platform.dnanexus.com/*"
}
}
},
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::yourAccountNumber:root"
},
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::yourBucketName",
"arn:aws:s3:::yourBucketName/*"
],
"Condition": {
"StringLike": {
"aws:Referer": "https://platform.dnanexus.com/*"
}
}
}
]
}Another improvement: You can transfer your data from one S3 instance to another (DNAnexus to AWS) at the rate of 250 GBytes per hour, including verification. Five years ago, the transfer speed was 10 GBytes per hour!
One final gotcha
One thing that has not changed in 5 years is the “data transfer out” fee. Amazon’s fee is $0.09 per GByte and DNAnexus’ fee is $0.13 per GByte. This fee is an understandable disincentive to keep you from moving your data around too much. In my case, moving our family’s WGS data to AWS will add over $100 to the final bill. It’s a little like losing all your money at baccarat and then finding out that you still owe the banque a commission before you leave the table. Not a big deal when you are a family, but when you are the UK Biobank expecting to grow to 15 petabytes over the next 5 years…well, you get the idea.
For the money, take a look at upstart competitors like Basepair or ixLayer.
[Update 2021-01-10: Do not forget to remove the DNAnexus API, called dx-toolkit!]
sudo apt-get remove --purge dx sudo apt autoremove sudo rm /etc/apt/sources.list.d/dnanexus.list
My WGS data is now available on Amazon S3
Read the blog post