This entry was cross-posted from DNAdigest on April 22, 2015.
Amazingly, the cost of whole genome sequencing is now 100,000 times less expensive than it was a dozen years ago. If the Tesla Model S followed this trajectory, you could buy one today for less than $1 USD. This super logarithmic decline puts genomics on par with desktop publishing or 3D printing—it has become something that you can affordably do yourself.
My wife, Kimberly, and I were excited about the prospect of having our genomes sequenced. Our daughter has autism, and like many parents of special needs children, we were eager to explore the underlying causes of her condition. We “got genomed” last year by enrolling in Illumina’s Understand Your Genome program. We received our whole genome sequencing (WGS) data, as well as limited predisposition and carrier screening for a number of Mendelian traits. As many DNAdigest readers know, the cost of WGS continues to drop in price, almost to the $1,000 genome that Illumina announced last year. Kimberly and I were intrigued to learn that we were both carriers of some rare genetic variants. Could our genetic idiosyncrasies be contributing to our daughter’s autism?
Our daughter has autism, and like many parents of special needs children, we were eager to explore the underlying causes of her condition. We “got genomed” last year by enrolling in Illumina’s Understand Your Genome program. We received our whole genome sequencing (WGS) data, as well as limited predisposition and carrier screening for a number of Mendelian traits. As many DNAdigest readers know, the cost of WGS continues to drop in price, almost to the $1,000 genome that Illumina announced last year. Kimberly and I were intrigued to learn that we were both carriers of some rare genetic variants. Could our genetic idiosyncrasies be contributing to our daughter’s autism?
After being sequenced, I followed the lead of DNAdigest contributor Manuel Corpas and posted my whole genome sequence online. I decided to publish my genome without restrictions in an attempt to lead by example. In the future, platforms like Repositive will make it easier for consumers to share genomic information and maintain privacy.
Kimberly and I recently launched a project on experiment.com to crowd fund the whole genome sequencing of our adult-aged daughter. In this project, we will look for genetic clues to her autism using family trio sequencing. Family trio sequencing is a powerful technique that can explain genetic conditions by looking at differences in DNA between Mom, Dad and an affected child.
We were thrilled when the sequencing project was funded the first day. In the process, we received feedback from other parents who wanted to learn more about the technique, so we added a stretch goal to cover publishing costs in an open access journal. The research paper will document our findings, as well as explain how family trio sequencing can be used to search for answers to health conditions and rare diseases.
Information sharing can indeed be very personal, but we find the possibility of catalyzing new areas of health research compelling. With this project, we hope to find clues that will contribute, if only in a small way, to a growing body of genomics research that supports a broader explanation of autism.
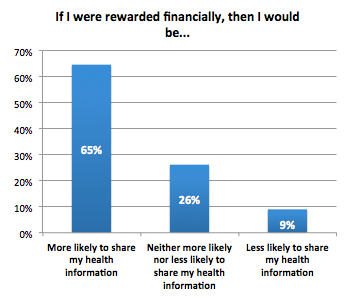
 I got genomed by Illumina
I got genomed by Illumina