In 2006, a Scientific American article written by George Church, “Genomics for All,” rekindled my interest in genomics. I went back to school in 2009 to contemplate the business of genomic medicine, and celebrated my MBA by writing a Wikipedia entry for the word, “Exome.” I was hooked.
Along the way, I realized that medical imaging and genomics are highly complementary: genomics informs or identifies conditions, and radiology localizes them. Sarah-Jane Dawson pointed this out at a Future of Genomic Medicine conference in 2014.
I have been a long-time listener to the intelligent and informative podcasts on Mendelspod, a site that connects people and ideas in life sciences. (Most nights you can find me listening to Mendelspod while I do the dishes.) I tuned-in sometime in 2012 and created a mental map of the industry by listening to every podcast I could find. A steady diet of listening to the latest developments in the industry has allowed me to talk about genomics with ease at meetups, tweetups and conferences. (OK, going back to school helped, too.) Somewhere along the way I decided that I would do something worthy of being interviewed on the show.
Well, last week I got my wish when my interview was posted on Mendelspod. I talked about our crowdfunded family trio sequencing project, autism, and even “coming out” of the research closet after being invited to speak at a conference in China last year. We explored parallels between my career in medical imaging and the future of genomic medicine (more in this blog post).
We concluded the interview by talking about Genomics Coffee, a (now defunct) discussion group that met in San Francisco.
Hosted by the Mind First Foundation, this conference enabled participants in the Personal Genome Project to hear first-hand how their health data could be used in research, especially mental health research. The second day of the conference, the “PGPalooza,” let PGP participants directly interact with researchers to select projects of interest and have their questions answered immediately.
James Tao graciously edited this 25-minute video of my talk about family trio sequencing and autism:
Also, special thanks to Alex Hoekstra, co-founder of Mind First, for the invitation to this event.
In this blog post, I look at whole genome sequence platforms for storage and discuss what might happen to “genomical” amounts of data.
Background
When I uploaded my whole genome sequence in September 2014 (about 10 months ago), few options existed for sharing personal genomic data. The usual suspects (Dropbox, Evernote and Figshare) were prohibitively expensive for large amounts of data. I knew about DNAnexus, but I saw it as a platform for researchers, not consumers. Well, times have changed. Fast.
A Battle of Platforms?
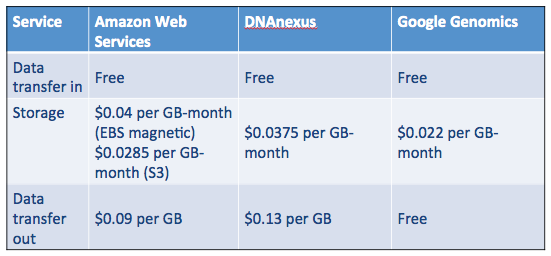
In addition to my original “roll your own” approach, DNAnexus and Google Genomics have emerged as major players for end-to-end genomics workflow. In the table below, you can see that storage costs for AWS S3, DNAnexus and Google Genomics are roughly the same. Everyone provides free uploads (we want your data!), but the cost for transferring data out of the systemvaries. Google Genomics does not charge for this, but instead charges for API access. For my current AWS storage, I pay about $4 per month to store my genome.
Table 1. Comparison of AWS, DNAnexus and Google Genomics storage costs. Your mileage may vary. Accessed July 7, 2015.
Ultimately, I selected DNAnexus over Google Genomics because their workflow API is well-developed and appealed to my roll-up-your-sleeves sensibility. (If you’re comfortable with command-line work, this platform is for you. BaseSpace, GenoSpace and Galaxy are other platforms to consider.) Google Ventures backed DNAnexus in 2011, so it’s difficult to predict what will happen in the long run. What we do know is that the value of their respective platforms will increase as more people join (and add data) to them. Google Genomics has partnerships with DNAstack, Autism Speaks and even DNAnexus. DNAnexus has partnerships with Baylor College of Medicine, WuXi NextCODE, and the Encode Project. The battle begins. If these two platforms can maintain standards-based interoperability, the competition is good for everyone.
Astronomical becomes Genomical: A Perspective on Storage
In this recent article about big data and genomics, the authors compare the field of genomics with three other Big Data applications: astronomy, YouTube and Twitter. In common with genomics, these domains: 1) generate large amounts of data, and 2) share similar data life cycles. The authors examine four areas–acquisition, storage, distribution, analysis–and conclude that genomics is “on par with or the most demanding” of these disciplines/applications. My previous experience in medical imaging (a field that arguably tackled the prior generation of “big data” issues) leads me to believe that genomics will come to epitomize Big Data to many more people before long.
If you look carefully at the projections in the figure above, we may run out of genomes to sequence (really?), which brings us back to storage. Where will we store all of this sequence data, especially as genomic medicine continues its inexorable move to the clinic?
Delete Nothing and Carry on
If the field of medical imaging is an indicator, deleting anything after it has been archived is the exception rather than the rule. The main reason for this is medicolegal — hospitals avoid the liability of not being able to recall an exam later by keeping everything. Although the incidence of requiring access to images after diagnosis is low, the consequence of not having access to the original diagnostic image is high. A former colleague suggested that about 5% of their medical archive customers use lifecycle management features to delete imaging exams. In medical imaging, customers more commonly use lifecycle management features to migrate images to less expensive storage devices over time. So, in genomics, you might migrate your sequence data stored on Amazon from solid state storage (most expensive) to S3 to Glacier (least expensive). But my best guess: we’ll delete nothing and carry on.
Yesterday, I presented preliminary findings at the 2015 Clinical Genome Conference in San Francisco from our family trio sequencing project. In this crowdsourced project on experiment.com, I looked for genetic clues to autism in our adult-aged daughter. While the talk focused on the “DIY” aspects of how to accomplish WGS sequencing, this post focuses on genetic findings.
Overview
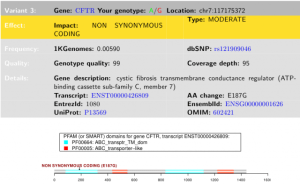
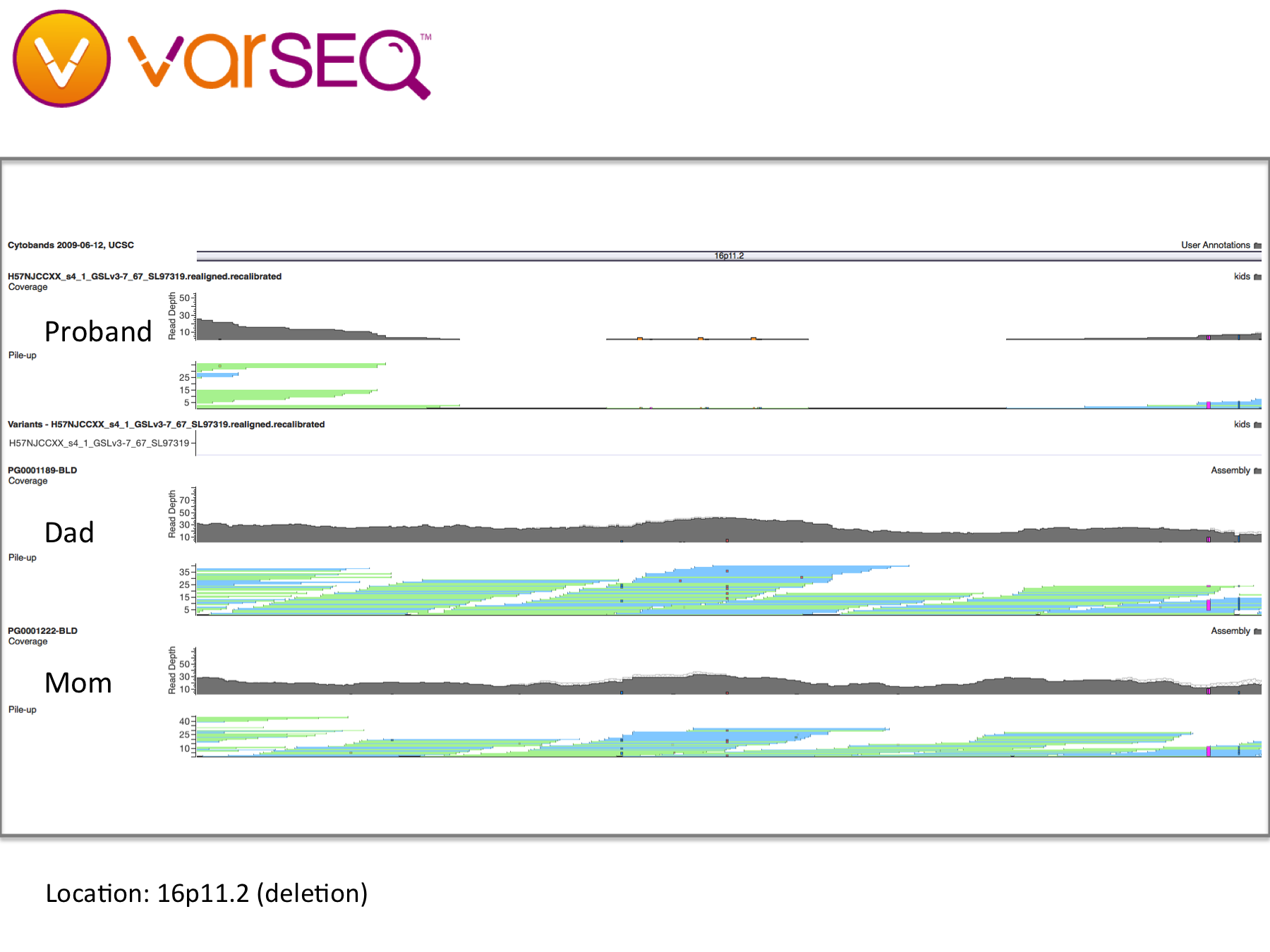
The project began with a crowdsourced effort to raise $1,750 to sequence our daughter’s genome, and took slightly more than two months to complete. After working with AllSeq and HudsonAlpha to obtain WGS data, we used VarSeq from Golden Helix to search for unique variants, as well as browse whole genome sequence data. After filtering our variant call data to focus on high quality exome variants, we examined 52 potentially damaging de novo and compound heterozygous changes suggested by VarSeq’s family trio analysis. Although this first approach did not yield clues specific to autism, it did suggest a number of secondary findings that are not addressed here. The second approach was to start with genes having known associations with autism and then look for them in our daughter’s DNA. Several curated databases have between 200 and 1200 genes, but again, none produced meaningful results. The third method was to look at known “hot spots” in autism genetics, such as variants in the NRXN1 gene, as well as known structural variation on chromosome 16. Changes to NRXN1 and so-called “16p” changes are discussed below.
Findings
NRXN1 – Deletions in NRXN1 are associated with a wide spectrum of developmental disorders, including autism. Our daughter has a 10bp exonic deletion (-GT repeat) followed by what appears to be a 9bp compound heterozygous deletion in NRXN1. Both deletions are partially present in both parents and overlap; the deletions appear to have been accumulatively inherited. Due to the high number of sequence repeats, copy number variation (CNV) should clarify the significance of this finding.
16p deletions – Deletions and duplications in this 593-kilobase section of chromosome 16 are widely associated with developmental issues, including autism. Our daughter appears to have dozens of deletions in this region, some inherited and some not. However, since the variants in our daughter’s DNA were called using a different software pipeline, it is difficult to draw meaningful conclusions (see “Limitations,” below). For example, some variants in our daughter’s DNA were shown to map to multiple locations on the genome, suggesting either large copy number variation or genomic regions that were difficult to map. Copy number variation (CNV) analysis will also elucidate this region. Once reprocessed, these findings may provide potential genetic clues to our daughter’s condition.
Limitations
My wife and I received our WGS data in March 2014. Our samples were sequenced at 30x coverage using Illumina’s HiSeq platform and then aligned and called with Illumina’s pipeline, Isaac. Our daughter’s DNA was sequenced in May 2015 at 30x coverage, but on Illumina’s newest platform, the Illumina HiSeq X Ten. The difference is that our daughter’s DNA was aligned using BWA, followed by variant calling with GATK “best practice” workflow. To accurately compare genomes in family trio analysis, all samples must be processed using the same software pipeline. Otherwise, variants may be aligned and called differently. My wife and I must go back to the (almost) original FASTQ data and start over. Although Illumina did not provide these files with our results, Mike Lin explains how to extract FASTQ files from Illumina data in this great blog series. Hint: it involves a utility called Picard (no relation). Until we reprocess our WGS data using the same bioinformatics pipeline, all results should be considered preliminary.
Conclusion
This project demonstrated that personal genomics is very real, and has the potential to answer complex medical questions. Today, answering those questions using whole genome data and family trio analysis requires a combination of genetic, bioinformatic and domain knowledge to reach meaningful conclusions. Validating those conclusions remains challenging, from rare diseases to complex conditions such as autism. Currently, personal genomics has a similar feel to “homebrew” computer clubs from the late ’70s–the community is still very small, collegial, and willing to share “tips and tricks” to advance the field.
Although we encountered some “dark alleys” during the analysis, our preliminary results suggest that family trio sequencing can indeed provide genetic clues to autism. We will continue to refine the analysis by reprocessing the data with the same pipeline, which should resolve questions in the 16p region, as well as the potential deletion in NRXN1. Further, CNV analysis should answer structural variation questions that are also known to be associated with autism spectrum conditions.
Acknowledgements
I would like to thank our backers and the team at experiment.com, as well as Gabe Rudy from Golden Helix. Gabe was very generous with his time, knowledge and insight. Finally, I would like to thank my wife, Kimberly, for her patience and fortitude.
This entry was cross-posted from DNAdigest on April 22, 2015.
Amazingly, the cost of whole genome sequencing is now 100,000 times less expensive than it was a dozen years ago. If the Tesla Model S followed this trajectory, you could buy one today for less than $1 USD. This super logarithmic decline puts genomics on par with desktop publishing or 3D printing—it has become something that you can affordably do yourself.
My wife, Kimberly, and I were excited about the prospect of having our genomes sequenced. Our daughter has autism, and like many parents of special needs children, we were eager to explore the underlying causes of her condition. We “got genomed” last year by enrolling in Illumina’s Understand Your Genome program. We received our whole genome sequencing (WGS) data, as well as limited predisposition and carrier screening for a number of Mendelian traits. As many DNAdigest readers know, the cost of WGS continues to drop in price, almost to the $1,000 genome that Illumina announced last year. Kimberly and I were intrigued to learn that we were both carriers of some rare genetic variants. Could our genetic idiosyncrasies be contributing to our daughter’s autism?
After being sequenced, I followed the lead of DNAdigest contributor Manuel Corpas and posted my whole genome sequence online. I decided to publish my genome without restrictions in an attempt to lead by example. In the future, platforms like Repositive will make it easier for consumers to share genomic information and maintain privacy.
Kimberly and I recently launched a project on experiment.com to crowd fund the whole genome sequencing of our adult-aged daughter. In this project, we will look for genetic clues to her autism using family trio sequencing. Family trio sequencing is a powerful technique that can explain genetic conditions by looking at differences in DNA between Mom, Dad and an affected child.
We were thrilled when the sequencing project was funded the first day. In the process, we received feedback from other parents who wanted to learn more about the technique, so we added a stretch goal to cover publishing costs in an open access journal. The research paper will document our findings, as well as explain how family trio sequencing can be used to search for answers to health conditions and rare diseases.
Information sharing can indeed be very personal, but we find the possibility of catalyzing new areas of health research compelling. With this project, we hope to find clues that will contribute, if only in a small way, to a growing body of genomics research that supports a broader explanation of autism.
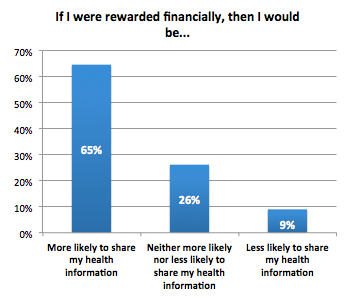
Are some consumers willing to sell their personal health information? It looks like the answer is “yes.” This week, I presented a paper at the IEEE International Conference on Data Mining in Shenzhen, China. This paper summarized the results of an online survey about consumers’ willingness to share de-identified health information, and whether their attitudes would change if a financial reward was offered. Here’s the abstract:
To realize preventive and personalized medicine, large numbers of consumers must pool health information to create datasets that can be analyzed for wellness and disease trends. To date, consumers have been reluctant to share personal health information for a variety of reasons. To explore how financial rewards may influence data sharing, the concept of Markets of Data (MoDAT) is applied to health information. Results from a global online survey show that a previously uncovered group of consumers exists who are willing to sell their de-identified personal health information. Incorporating this information into existing health research databases has the potential to improve healthcare worldwide.
During the presentation, I argued that patient populations for both rare and common diseases can look similar, especially when looking at disease subtypes. When considering relatively common diseases such as diabetes, schizophrenia, and autism spectrum disorders, a single hospital in the U.S. will not see enough patients for a given disease subtype to make meaningful conclusions. On average, U.S.-based hospitals do not have enough patients to solve disease questions without sharing health information.
For this survey, a global panel of 400 participants was selected at random by AYTM, an online market research tool. Questions were based on a previous health information sharing survey, with additional questions about sharing with financial reward. I received 400 responses from 59 countries in less than two hours. U.S.-based respondents overwhelming believed that their health information was worth more than $1000, but the global average was around $250 when the U.S. was excluded. For these participants, both their motivation and the amount of data shared increased with financial reward. Keep in mind that these participants were paid to respond to the survey, so they represent a kind of self-selected group. Nevertheless, monetizing health information sharing produced a surprising result, demonstrating that an alternative source of health information may exist for research purposes.
In March 2014, my wife and I “got genomed” by enrolling in Illumina’s (now Genome Medical’s) Understand Your Genome (UYG) program. UYG requires participants to order this whole genome sequence (WGS) test from their physicians due to uncertainties surrounding the delivery of genomic results in the U.S. Illumina is careful to point out that the service “…has not been cleared or approved by the U.S. Food and Drug Administration” and “you will not receive medical results, or a diagnosis, or a recommendation for treatment.” Our family physician signed the request in November 2013, and we received our results in February. Fortunately, no surprises, but the UYG program only covers these Mendelian disorders for now. We flew to San Diego a few weeks later to listen to talks by genomic researchers and discuss our results with genetic counselors. As part of this one-day seminar, we each received an iPad Mini that was pre-loaded with our results, as well as a portable hard drive that contained our raw sequence data.
I received my WGS data on this encrypted hard drive (about 100GB).
After we arrived home, the next step was to find a public “home” for my sequence data (to share without restrictions). What I learned is that uploading your genome anywhere is a challenge, mostly because the dataset is so big.
My genome data and results are now in the public domain, freely available to download under a Creative Commons (CC0) license. Uploading the data took two days over a 3Mbps connection, so you may want to read the clinical report and sample report instead.
ftp://ftp.startcodon.org <– I decommissioned the ftp server
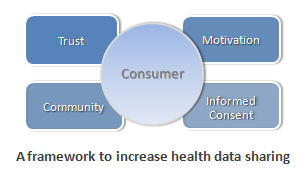
Sharing personal health information is essential to create next generation healthcare services. To realize preventive and personalized medicine, large numbers of consumers must pool health information to create datasets that can be analyzed for wellness and disease trends. Incorporating this information will not only empower consumers, but also enable health systems to improve patient care. To date, consumers have been reluctant to share personal health information for a variety of reasons, but attitudes are shifting. Results from an online survey demonstrate a strong willingness to share health information for research purposes. Building on these results, the authors present a framework to increase health information sharing based on trust, motivation, community, and informed consent.
The take-home messages from the paper are:
Consumers are willing to share health data under the right conditions.
Education seems to play a strong role.
Consumers want to be connected to their data.
Develop models to encourage sharing.
My favorite part of the talk was explaining how I repeated the survey using an online market research tool. Our respondents were extremely educated — 59% had a Master’s level education or higher — so I wondered if education played a role in their willingness to share. In less than two hours, I posted the survey and received 100 responses (compared with the nine months it took to receive 128 IRB-consented responses). This time, about 20% of the respondents had a Master’s level education or higher, still higher than the US average of 10%, according to the US Census Bureau. Nevertheless, overall attitudes toward sharing were similar. In particular, respondents who were not willing to share their health information tended to have little or no college experience. Although both surveys operated on convenience samples, the results suggest that education plays a role, perhaps because education can change our perception of the risks and benefits associated with sharing health data. Interestingly, these results and conclusions were similar to those found in a recent report published by the Health Data Exploration project sponsored by the Robert Wood Johnson Foundation. More information about this project:







 I got genomed by Illumina
I got genomed by Illumina